What is SAP (HANA) In-Memory Computing
A traditional analysis of large volume of data is usually slow because the application logic must fetch the data from database which is not stored entirely in memory. When a query is being processed on a large volume, the database instance swaps the rows back and forth from the file system. Disk reads (and writes) are slow. The analysis is typically done on columns (ex: sum of salary, total number of invoices etc), where are the operations store the data in a row-wise structure. Although the processing is required on a few columns (since the analysis involves summation, averages etc.) of data, all rows are required to be read. Even if several application or DB cluster nodes are installed, the entire query has to run on a single instance of the application or database.
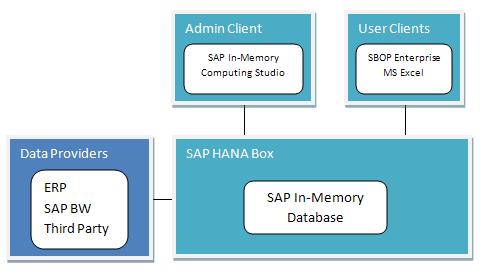
SAP HANA (High-Performance Analytic Application) provides database within memory. It uses columnar-databases (with this methodology, if one is working on aggregates, only the columns worth of data is read and is therefore faster compared to reading entire table), MPP (massively parallel processing: a query can be processed by multiple instances) and data compression to help one create analytic models on real-time data much faster.

SAP HANA (High-Performance Analytic Application) provides database within memory. It uses columnar-databases (with this methodology, if one is working on aggregates, only the columns worth of data is read and is therefore faster compared to reading entire table), MPP (massively parallel processing: a query can be processed by multiple instances) and data compression to help one create analytic models on real-time data much faster.


Comments
Post a Comment